How to Choose the Right LLM for AI-Assisted Coding
New models drop every week, each claiming to top the coding benchmarks. How do you actually pick the right one for AI-assisted coding?
The short answer: ignore the hype and focus on what actually predicts performance in your workflow.
The Problem with Coding Benchmarks
Traditional coding benchmarks like HumanEval measure isolated function-writing tasks, and even more sophisticated benchmarks like SWE-bench test single-shot issue resolution. A model can ace these benchmarks and still struggle in real agentic coding workflows, which require iterative multi-turn collaboration, effective tool use, and managing context across files over extended sessions.
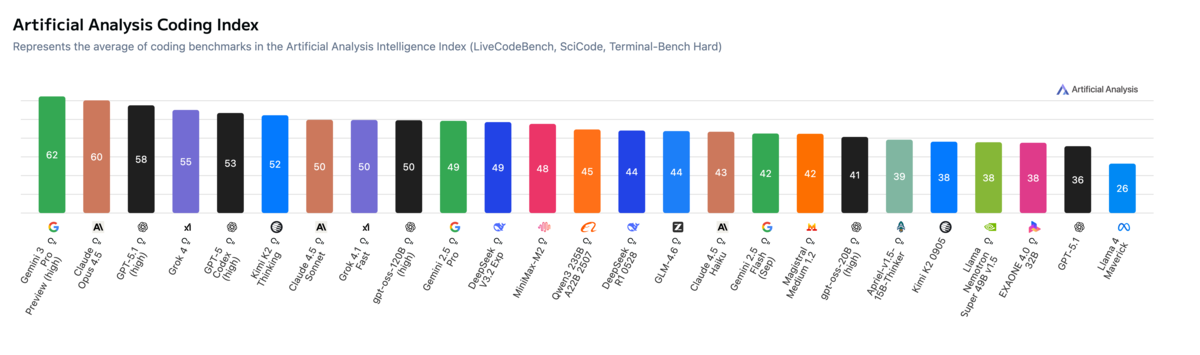
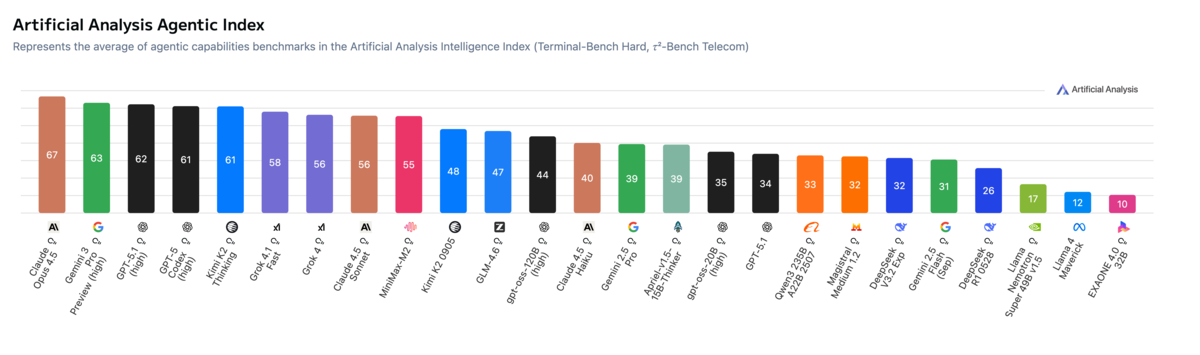
The Agentic Index: A Better Signal
I've found the Artificial Analysis Agentic Index to be a much better predictor of how a model will perform for AI-assisted coding. It measures how well models handle tool use and multi-step problem solving. For coding, this translates to how well a model navigates codebases, coordinates changes across files, uses search and editing tools, and maintains context over extended sessions.
A good example: DeepSeek R1 0528 scores well on coding benchmarks but poorly on the agentic index. It might be fine for writing standalone scripts, but it won't make effective use of the tools in modern AI coding platforms. In practice, this means it might write good code when given explicit instructions, but may struggle to navigate your codebase, search for relevant context, or use tools and MCPs effectively. The rankings shift significantly when you measure what actually matters.
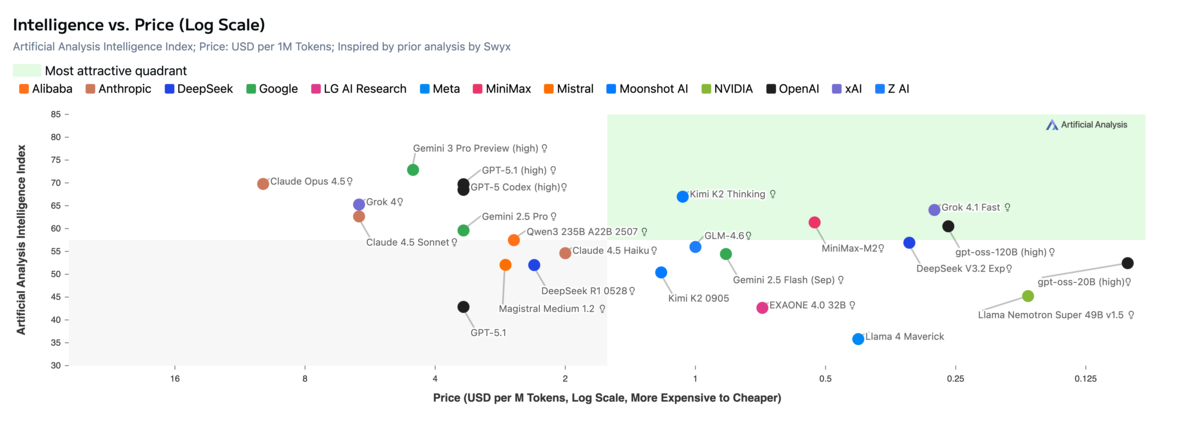
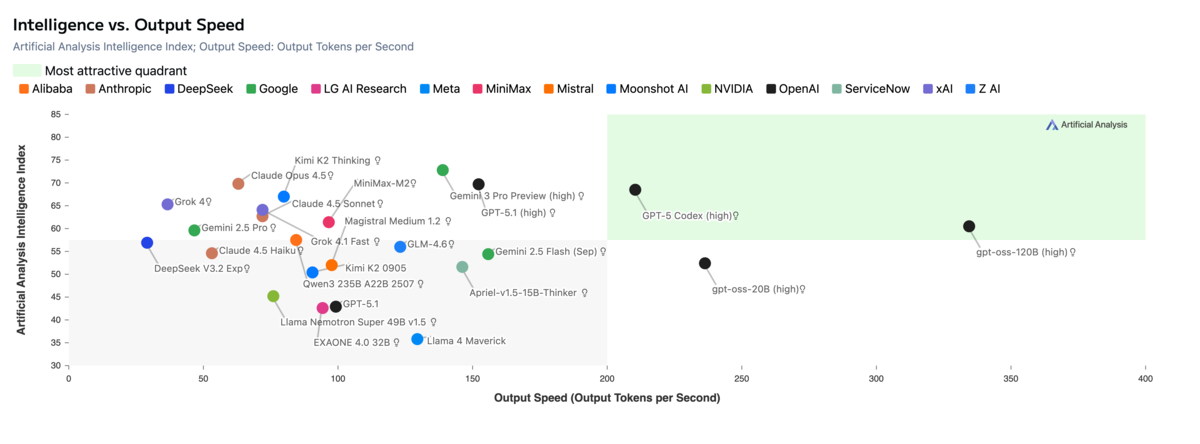
Evaluating Trade-offs
You don't always need the absolute best model. Artificial Analysis provides scatter plots that let you visualize trade-offs between performance, cost, and speed. Look for models in the upper-right quadrant: high performance, lower cost. The sweet spot is often models one tier below the frontier that deliver 90% of the capability at a fraction of the price.
Match the Model to the Phase
In my previous post, I covered the three phases of AI-assisted coding: planning, implementation plan creation, and implementation. Different phases have different requirements.
For planning and creating the implementation plan, I use high-reasoning models. Mistakes at this stage are expensive: a flawed plan means wasted implementation time, or worse, shipping bugs that a more thorough analysis would have caught. I want thorough analysis, not speed. For implementation, I switch to faster, cheaper models. The thinking is already done; the AI just needs to execute a clear plan.
Right now, I use Claude Opus 4.5 for planning and implementation plan creation, then switch to Cursor's Composer 1 model for implementation. These specific models change constantly as new ones release, so use artificialanalysis.ai to stay current on the trade-offs.
Always Vibe Check
Even the best benchmarks can mislead. Gemini 3 Pro currently dominates both the coding and agentic benchmarks, but when I tried it for planning, it kept jumping straight to solutions instead of exploring the problem space with me. It failed the vibe check for that use case, despite topping the leaderboards.
Always test models in your actual workflow before committing. Run 2-3 representative tasks from your actual workflow. Pay attention to whether the model collaborates or steamrolls, whether it asks clarifying questions, and whether it uses tools appropriately. Benchmarks are a starting point, not the final answer.
The Takeaway
Don't chase benchmark leaderboards blindly. Use the agentic index as a better starting point, evaluate trade-offs based on your phase and priorities, and vibe check before committing. Artificial Analysis is your friend for staying current as the model landscape shifts.
I teach workshops on AI-assisted development techniques, helping teams build effective workflows with these tools. If you're interested in leveling up how your organization uses AI for coding, let's talk.

Dr. Randal S. Olson
AI Researcher & Builder · Co-Founder & CTO at Goodeye Labs
I turn ambitious AI ideas into business wins, bridging the gap between technical promise and real-world impact.


